编者按:近日,Kaggle数据科学竞赛的多个赛事落下帷幕,我校771771威尼斯.Cm2020级中美合作办学项目的两支队伍发挥出色,获得佳绩。在第一支队伍中,国合班本科生李祯宁同学在Kaggle数据科学竞赛-Image Matching Challenge 2023和Kaggle数据科学竞赛Google Research - Identify Contrails to Reduce Global Warming比赛中分别获得铜牌(Top19%)和银牌(Top5%)奖项;第二支队伍Satoshi Shimomoto由谭以宁、秦浩然、陈予贤三人组成,他们在Kaggle数据科学竞赛GoDaddy - Microbusiness Density Forecasting,Kaggle数据科学竞赛 AMP®-Parkinson's Disease Progression Prediction和Kaggle数据科学竞赛March Machine Learning Mania 2023三场比赛中分别斩获三枚银牌(Top2%、Top4%、Top5%),三场比赛的参赛人员分别为GoDaddy - Microbusiness Density Forecasting:谭以宁、秦浩然、陈予贤;AMP®-Parkinson's Disease Progression Prediction:谭以宁、秦浩然;March Machine Learning Mania 2023:谭以宁。编者邀请获奖同学讲述他们的奋斗故事!
Kaggle是一个进行数据发掘和预测竞赛的在线平台,目前拥有超过80万名数据科学家的用户。Kaggle的使命是通过众包的方式,解决世界上最棘手的问题,同时推动机器学习和数据科学的发展。在Kaggle上,企业或研究者可以发布一些数据和问题,提供一定的奖金,来吸引全球范围内的参赛者来提出解决方案。参赛者可以下载数据,分析数据,建立模型,提交结果,查看排名,并与其他参赛者交流学习。Kaggle不仅是一个竞赛平台,还是一个数据科学家学习、分享、合作的社区。在Kaggle上,用户可以浏览各种高质量的数据集、运行和编写代码、发表和阅读文章、寻找和发布工作机会等。
一、计算机视觉团队奋斗记
李祯宁同学自入学以来就对数据挖掘表现出极高的兴趣,她始终梦想着运用所学的专业知识解决各类工程类和学术类问题,以此来展示自己的才华和能力。而这次Kaggle大赛无疑为她提供了一个宝贵的机会。因此她便开始进行比赛的筹备,并且希望可以在比赛中学习新的技术,提升自身能力。
赛题初探


李祯宁同学共参加了kaggle竞赛的两项赛事,分别是Image Matching Challenge 2023和Google Research - Identify Contrails to Reduce Global Warming。
1.Image Matching Challenge 2023
Image Matching Challenge涉及图像匹配任务。图像匹配是计算机视觉领域的一个重要任务,它涉及从不同视角、光照条件和尺度的图像中识别相同的物体或场景。Image Matching Challenge 2023旨在推动这一领域的技术发展,要求参赛者利用机器学习和人工智能技术开发更强大、更鲁棒的图像匹配算法。

任务要求对不同角度的图像进行关键点匹配。通过阅读论文,团队先确定了算法流程和优化思路。主要分为三个阶段:特征检测与提取、特征匹配和几何验证、结构重建,其中kaggle官方为参赛者实现了最后的几何验证和结构重建部分,因此团队的优化重心放在了特征检测与提取和特征匹配这两个阶段。
2.Google Research - IdentifyContrails to Reduce
Global Warming
Contrails 是“凝结轨迹”的缩写,是在飞机发动机排气中形成的线状冰晶云,由飞机飞过大气中的超潮湿区域时产生。持续的尾迹对全球变暖的贡献与它们为飞行所燃烧的燃料一样多。
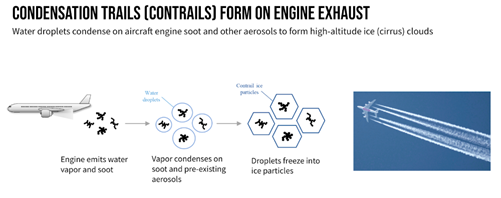
在本次比赛中,我们需要使用地球静止卫星图像来识别航空轨迹。原始卫星图像是从GOES-16 Advanced Baseline Imager (ABI)获得的,它在Google Cloud Storage上公开可用。

模型初尝试
1.Image Matching Challenge 2023
2023年5月,经过一个月的初步尝试以及阅读论文,我达成了一个初步的模型方案:

首先利用已经预训练的图像分类模型Efficientnet对每张图像进行特征提取,选择倒数第二层的特征向量作为输出,计算两张图像之间的特征向量的余弦相关性作为筛选指标,指定一个阈值作为筛选;然后使用SIFT对所有图像对进行特征提取和特征匹配(adalam),从中筛选出特征点比较多的图像对作为最终图像对;采用多模型串联并联方式提取匹配点,对三种图像尺度640,800,1200分别利用LoFTR和DKM提取特征点,再对提取到的特征点进行聚类,从中裁剪出包含80%的特征点所在区域,再对该区域进行LoFTR和DKM特征提取。最后将两次提取到的特征点进行concat。
此解决方案取得了不错的成绩,但效果仍不够好,模型还需要进一步进行优化。
2.Google Research - Identify Contrails to Reduce
Global Warming
2023年5月,经过数据统计,我发现分割飞机航迹这个赛题的数据样本分布是非常不均衡的,训练集当中大部分的图片是不包含飞机航迹的,因此我们把这部分数据进行了剔除。而在包含飞机航迹的图片中,航机像素的占比又非常的低,针对样本比例分布不平衡的特点,我们采用了Focal loss进行拟合。模型架构采用Unet结构,在Unet架构下,我采用了不同的encoder来特征提取。
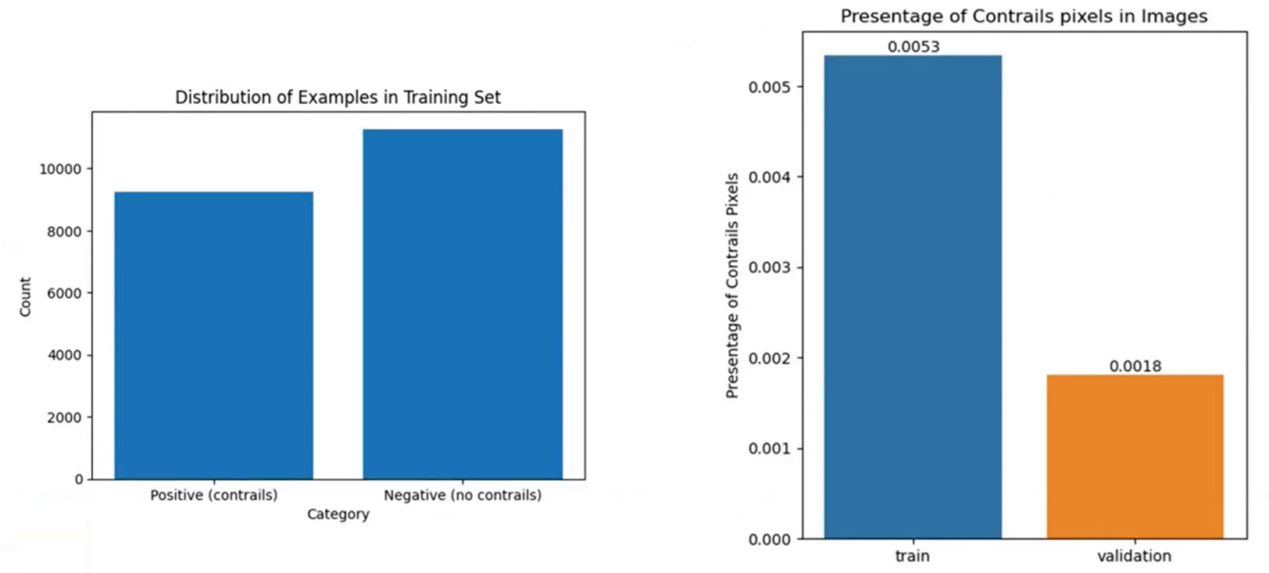
Focal loss 是一种用于解决样本分布不平衡问题的损失函数,特别是在分类任务中。它是在交叉熵损失函数的基础上进行修改的,目的是减少类别间的不平衡问题。
Focal loss的主要思想是降低容易分类样本的权重,从而更加关注那些难以分类的样本。具体来说,当模型在容易分类的样本上取得正确预测时,Focal loss 会给这些样本一个较小的权重;而在难以分类的样本上取得正确预测时,会给这些样本一个较大的权重。这样,模型会更加关注那些难以分类的样本,提高模型在不平衡数据集上的性能。
模型再优化
1.Image Matching Challenge 2023
2023年6月,在建立模型并取得了初步成果后,团队围绕图像匹配寻找着更加合适的模型。
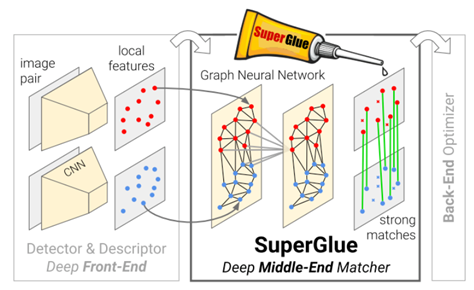
在阅读了图像匹配领域相关论文后,团队建立了SuperPoint+SuperGlue的图像匹配模型。其中,SuperPoint设计了一种自监督网络框架,能够同时提取特征点的位置以及描述子。相比于patch-based方法,提出的算法能够在原始图像提取到像素级精度的特征点的位置及其描述子。SuperGlue是一种特征匹配网络,它的输入是2张图像中特征点以及描述子(手工特征或者深度学习特征均可),输出是图像特征之间的匹配关系。相比于LoFTR和DKM,SuperPoint和SuperGlue可以让模型更好地关注图像中的重要区域,从而提高学习效果。
2.Google Research - Identify Contrails to Reduce
Global Warming
在确定好模型的基础架构后,我们确定了最终方案,其中,数据处理阶段:由于数据量庞大,去除所有无标签卫星图片,保存human_pixel_masks,同时normalize后转为numpy文件保存,节省空间以及便于训练读取。模型训练阶段:采用图像大模型训练,分别使用增强(augment)和不增强(no augment)的训练方式,采用位置变换(翻转与旋转);图片数据尺寸在一定范围内增大,训练效果越好。竞赛中所用尺寸包括:512x512,768x768,864x864,推理阶段:单模型使用TTA增强(翻转与旋转变换)预测结果,再将不同模型的预测结果通过加权融合取阈值获得最终推理结果。
2023年7月和8月,两场比赛落下帷幕,两次比赛历时3个月,吸引了来自全球多个国家的494个队伍和954个队伍报名,经过激烈的角逐,共决出10枚金牌、50枚银牌和50枚铜牌,团队分别了获得铜牌(Top 19%)和银牌(Top 5%)。
参赛感悟

李祯宁:我经历了许多困难和挑战,但也收获了许多宝贵的经验。首先,我发现数据分析和建模能力是关键。在比赛中,我们需要对数据进行深入的分析和挖掘,找到数据中的规律和趋势,并建立有效的模型来预测结果,我相信这些经验将对我未来的学习和工作产生积极的影响。同时,Kaggle也提升了我的能力,包括数据分析和处理、深度学习算法应用、编程技巧等方面的能力。这些能力是保研面试中重要的加分项,能够帮助我更好地展示自己的专业素养和潜力,目前我已被复旦大学771771威尼斯.Cm录取。我将继续努力提高自己的技能和能力,为未来的挑战做好准备。
二、Satoshi Shimomoto团队“奋斗”记
谭以宁、秦浩然、陈予贤三位同学自入学以来就对数据挖掘表现出极高的兴趣,他们很早就达成了共识一起参加各类数据挖掘比赛,并组成了队伍Satoshi Shimomoto。恰逢这几场Kaggle数据挖掘类竞赛,他们决定参加以锻炼自己的能力。
赛题初探
Satoshi Shimomoto团队共参加了kaggle竞赛的三项赛事,分别是GoDaddy - Microbusiness Density Forecasting,AMP®-Parkinson's Disease Progression Prediction和March Machine Learning Mania 2023。其中三项比赛的参赛成员分别为谭以宁、秦浩然、陈予贤;谭以宁、秦浩然;谭以宁。
1.GoDaddy - Microbusiness Density Forecasting

这场比赛的目标是预测给定地区的月度微型企业密度,需要根据美国县级数据开发一个准确的模型。本次竞赛旨在帮助决策者了解微型企业,这是一种非常小的实体不断增长的趋势。额外的信息将使新的政策和计划能够提高这些最小企业的成功率和影响力。
2.AMP®-Parkinson's Disease Progression Prediction

这场比赛的目标是预测MDS-UPDR评分,该评分衡量帕金森病患者的进展情况。运动障碍协会赞助的统一帕金森氏症评定量表修订版(MDS-UPDRS)是对帕金森氏症相关的运动和非运动症状的综合评估。本次竞赛要求开发一个模型,该模型根据帕金森病受试者与年龄匹配的正常对照受试者的蛋白质和肽水平数据进行训练,旨在帮助提供重要的突破性信息,了解哪些分子会随着帕金森病的进展而变化。
3.March Machine Learning Mania 2023

这场比赛的目标是预测2023年NCAA疯狂三月篮球锦标赛(March Madness)中每场比赛结果。要求结合丰富的历史数据和先进的机器学习技术,成功地开发出了一个能够准确预测比赛结果的模型。
模型建立
1.GoDaddy - Microbusiness Density Forecasting
在这个比赛中,我们采用了多种策略:
- 对county state等进行编码encode,处理一些脱离分布的异常值anomaly data。
- 计算density和active的lag特征,对每个月的数据都加一个之前n个月的density,做九个月,如果是最早的就用数据本身代替。
- 加county的经纬度Latitude and longitude特征,加last active。
- 引用外部数据如出生人数birth性别gender死亡人数death count数据距离开始的月份。
- Stacking loss_function MAPE的first layer catboost回归lgbm回归xgb回归第二层catboost对参数进行一定的微调adjust the parameter设置active阈值150训练集设置最新active大于阈值的训练时将标签映射到一个区间中。
- 真实值-预测值得到残差,再用lgbm训练这个残差最终将第一个预测结果加上残差得到最终结果Last active小于阈值的直接等于之前的Trick。
- 再将该方法和仅仅使用上一个月density的baseline的线性函数进行加权,异常值直接给固定值 引用county的人口数据将之前的更新为21年的。发现active都是整数,需要将active四舍五入。
2.AMP®-Parkinson's Disease Progression Prediction
对于这个时序预测问题,预测MDS-UPDR评分。我们采取了以下策略:
- 对于updrs1-3线性回归,对于updrs4多项式回归。
- 对updrs4设置clip,第54月之前水平。
- 加入protein蛋白质数据扰动,计算蛋白质与updrs的相关系数,找到和1-3相关系数高,和4相关系数低的protein代号,使用该蛋白质数据计算扰动。
- 设置mask range,分箱寻找扰动,mask的部分加扰动,其余部分不加trick。
3.March Machine Learning Mania 2023
对于这个比赛,我们侧重于特征工程。我们建立了一些强相关的特征:获胜次数、损失数量、胜场平均比分差距、损失的平均分数差距、获胜率、平均分数差距、获胜队伍的seed、失败队伍的seed、获胜球队在赛季中的胜率、输球球队在赛季中的胜率、赛季中获胜球队的评分、赛季失败球队的评分等。这些特征都是基于丰富历史数据和先进机器学习技术构建出来的。我们通过这些特征成功地开发出了一个能够准确预测比赛结果的模型。
2023年4月,5月和6月,三场比赛落下帷幕。三场比赛历时3个月,分别吸引了来自全球多个国家的3547支队伍,1805支队伍和1033支队伍报名参加。经过激烈的角逐,来自我校的队伍Satoshi Shimomoto分别了获得三枚银牌(Top 2%,Top 4%,Top 5%)。
参赛感悟

谭以宁:作为Satoshi Shimomoto团队的一员,我深感荣幸。在这次Kaggle数据科学竞赛中,我们团队充分发挥了各自的专业技能,共同完成了一项艰巨的任务。我个人在比赛中主要负责模型的设计和优化,这是一项既具有挑战性又需要深厚专业知识的任务。在比赛过程中,我不断学习新的知识和技术,对模型进行持续的优化和改进。当得知我们团队在比赛中取得了优异的成绩时,我感到无比的喜悦和自豪。这是对我们团队努力的认可,也是对我们未来持续奋斗的巨大激励。kaggle数据科学竞赛的经历也为我进行国外高校的申请提供了很大助力。通过参与竞赛,我可以展示自己的创新能力和解决问题的能力,这些能力是高校在选拔研究生时非常看重的能力之一。

秦浩然:作为Satoshi Shimomoto团队的一员,我在这次Kaggle数据科学竞赛中负责模型训练和调优,这是一项需要深厚机器学习知识和丰富实践经验的任务。在比赛过程中,我不断尝试新的模型结构和参数设置,以提升模型的性能。每当看到模型性能有所提升时,我都会感到无比的喜悦。当得知我们团队在比赛中取得了优异成绩时,我感到非常激动和自豪。这不仅是对我们团队努力的认可,也是对我们专业技能和团队合作精神的肯定。同时,竞赛中的优秀表现也可以为我在国外高校的申请中赢得更多的关注和认可,增加被录取的机会。

陈予贤:参加这次Kaggle数据科学竞赛是我人生中一次非常宝贵的经历。作为Satoshi Shimomoto团队的一员,我主要负责数据预处理和特征工程。这需要我具备扎实的数据处理技能和敏锐的业务理解能力。在比赛过程中,我深入研究了各种数据处理技术,并尝试了多种特征工程方法。虽然过程充满了挑战,但看到我们的模型性能不断提升,我深感满足。当得知我们团队在比赛中获得了银牌时,我感到无比激动和自豪。这是对我们团队努力和付出的最好回报。同时,Kaggle数据科学竞赛的经历为我积累了一定的科研经验,对于我在保研时的面试和科研能力展示有着很大的帮助,目前我已被西北工业大学771771威尼斯.Cm录取。
师说心语

陈云亮:作为这次比赛的指导老师,我非常欣喜地看到学生们在比赛中展现出的热情和才华。这次比赛是一次极好的机会,让学生们深入了解了数据挖掘的原理和方法,锻炼了他们的实践能力和团队协作精神。最后,我要感谢所有参与比赛的学生们,你们的努力和付出让我深感骄傲。相信你们在未来的学习和工作中,将继续发挥自己的潜力,取得更加出色的成绩。

阎继宁:很高兴能够参加这次Kaggle数据科学竞赛的指导工作。看到学生们通过团队合作、创新思维和实践经验不断提升自己的数据挖掘技能,我感到非常欣慰。你们在遇到挑战时能够积极思考、寻求解决方案,不断尝试、不断改进,最终取得了优异的成绩。我相信,在未来的比赛中,他们一定会取得更加优异的成绩,为学校争光添彩。
图片 :李祯宁
文字:谭以宁 秦浩然 陈予贤
审核:李国昌 林小艳
校对:闫维蓉
版权所有 Copyright © 771771威尼斯.Cm(中国)官方网站-App Store


